
A Unicode Tutorial
In last month's Help Desk, we looked at the basics of PC character sets and encoding methods, focusing on JIS encoding (a 7-bit code used frequently for exchanging Japanese data over networks) and Shift-JIS encoding (widely used for processing Japanese on Windows 3.x PCs). This month, we'll turn our attention to Unicode, a relatively new 16-bit encoding method that has already been implemented on Microsoft's Windows NT operating system. Unicode is quickly gaining widespread support throughout the personal computing industry.by Steven Myers
Unicode began life as a coll-aborative effort between Xerox and Apple. The objective was to develop a character encoding alternative to the code page model. As I discussed in last month's Help Desk, many of the problems with the code page model are related to interoperability difficulties among the different code pages. These problems stem from the fact that code pages for most languages -- especially those requiring double-byte character codes -- were not planned for originally; rather, they evolved over time in a disorganized, ad hoc fashion. Unicode, therefore, was designed to be a universal all-encompassing character encoding method, one capable of supporting all of the world's languages without having to resort to complicated conversions or mappings between character sets.
The Unicode Consortium, formed in 1991, now includes such companies as Microsoft, IBM, Hewlett Packard, Novell, and Sybase. From 1991 to 1992, the Unicode Consortium and the International Standards Organization (which had theretofore been working on a separate, but similar, encoding standard) worked together to combine their efforts into a single coding method. The resulting standards, Unicode 1.1 and ISO 10646 -- both published in 1993 -- are identical. Japan recently released JIS X 0221-1995, its own national standard based on the ISO 10646 document. In addition to Windows NT, Unicode has started to appear in several other commercial products, including Apple's Newton PDA (personal digital assistant) and Novell's NetWare 4.01 Directory Services.
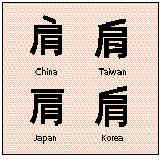
Examples of characters that were "unified"
Unicode basics
In contrast to JIS and Shift-JIS, both of which incorporate single-byte characters into the encoding scheme, every character in Unicode is represented by a distinct 16-bit code value. This makes it possible to represent a total of 65,536 characters with the Unicode system. Members of the Unicode Consortium have so far assigned characters to over 35,000 of these positions. These characters include a total of 20,902 kanji, which were taken from various Chinese, Japanese, and Korean character sets (originally containing a total of over 120,000 characters).The Unicode Consortium used a process called "Han unification" (sometimes referred to as "CJK unification") to eliminate redundant characters, thereby reducing the original ideographs down to a more manageable number. The basic idea behind Han unification is to find characters that are common to two or more of the languages, and to "unify" them by assigning a single code point in the Unicode encoding space. For example, the figure on this page below shows the mainland Chinese, Taiwanese, Japanese, and Korean versions of an ideograph that was deemed to be essentially the same character by the ISO SC2/WG2 Ideographic Rapporteur Group -- a team of experts from China, Japan, Korea, Taiwan, the US, Vietnam, and Hong Kong. These four previously separate characters, therefore, were unified into a single character in the Unicode scheme. The differences in appearance of the ideograph thus become merely an issue of what font is used rather than being a character encoding issue.
Encoding space
The figure on page 10 shows a rough diagram of the current use of Unicode encoding space, depicted as a 256-row by 256-cell matrix. The 35,000-plus Unicode code positions to which characters have already been assigned are enough to handle virtually every character commonly used in modern languages today (referred to by the Unicode Consortium as "scripts in use by major living languages"). The code space designated as "private use" can be used by individual applications for user-defined characters, such as the less common Japanese kanji used mainly for personal names.One very pertinent and controversial issue involves the criteria for deciding which CJK ideographs will be assigned code points in the remaining free space. According to the Unicode Consortium, each country participating in the Ideographic Rapporteur Group (IRG) is in the process of submitting "vertical extension" requests to SC2/WG2. If approved, these additional characters would be added to ISO 10646 and to Unicode.
At present, the following numbers of new characters have been submitted to the IRG:
China 8,279 characters
Japan 1,699 characters
Korea 2,149 characters
Taiwan 7,350 characters
Vietnam 1,775 characters
In addition to these already-submitted proposals, Hong Kong and Singapore are also developing extension proposals that would encode a number of characters specific to Cantonese and to Singapore, respectively.
When the IRG completes its task of identifying, collating, and unifying redundant characters, the approved ideographs will be submitted to the parent committee, SC2/WG2, which then will decide where to encode each of the new characters. Even after addition of the proposed extensions, however, a large number of Han ideographs will remain unencoded. The Unicode Consortium therefore expects that, in the future, it may become necessary to extend Unicode to support large collections of additional characters, such as older kanji or alphabets for rare scholarly languages.
To prepare for this possibility, the ISO 10646 standard has a set of 32-bit characters that could be made accessible from Unicode. One 1,000-character section of 16-bit Unicode code points has been reserved for "high" words, and another 1,000-character section has been reserved for "low" words. By using an algorithm to combine the high-word codes with the low-word codes, one million new codes can be created.
Unicode's strengths and limitations
Compared to encoding methods such as JIS and Shift-JIS, which mix single- and double-byte characters in their encoding, Unicode offers a number of attractive advantages to users and developers of international software. For example, data from just about any language in the world can be represented in a standard, plain-text format. This is particularly useful for such tasks as sending multilingual documents over networks or maintaining a multilingual database. Also, it will no longer be necessary for an application to take multiple code pages and DBCS (double-byte character set) string parsing into account. Much of the extra work for developers in providing an application with support for additional languages is thereby eliminated.Despite its numerous advantages, Unicode faces some fairly formidable obstacles to widespread acceptance. Being a relatively new technology, the Unicode standard is still in a constant state of flux, and a fair amount of debate is taking place between countries over the proper inclusion and subsequent representation of characters. (For a discussion of recent criticism in Japan related to this process, see "Technically Speaking" on page 15.)
One obstacle is that applications and fonts that support Unicode are still not widely available. For systems that handle primarily Western European languages, Unicode adds a hefty amount of overhead -- nearly twice the storage space is required. Presumably for these reasons, none of Microsoft's Windows 95 versions supports Unicode; Windows 95 opts instead for the same code page model that was used by Windows 3.1.
Although Unicode has been left off of Windows 95, the inclusion of Unicode support in Windows NT signifies a strong commitment by Microsoft to Unicode as the character encoding standard of the future. Furthermore, as technology continues to improve -- and data size and memory constraints become less of a concern -- there is little doubt that Unicode will eventually come into widespread use.ç
For further information on Unicode, contact:
The Unicode Consortium
PO Box 700519
San Jose, CA 95170-0519
USA
Phone +1-408-777-5870
Fax +1-408-777-5082
WWW: http://www.unicode.org
